
Media intelligence becomes operationally valuable when it runs continuously. A team should not need to manually upload every file, copy every result, or rebuild the same extraction workflow for each archive, campaign, game, lecture, or review queue. VectorMethods uses VideoVector to connect LLM-based video extraction, AI metadata extraction, search, exports, and webhooks into automated media pipelines.
The core workflow starts with cloud-connected ingestion. Media can enter from storage systems such as GCS, S3, Azure, and R2, or through application-controlled uploads. Once files arrive, VideoVector can run repeatable prompt executions, generate time-stamped metadata, create asset-level analysis, index searchable context, and prepare outputs for downstream delivery. The media workflow automation layer turns media processing into a repeatable operation instead of a one-off review task.
Automation is useful because media workflows usually cross systems. An archive team may need extracted descriptors in a catalog. A sports team may need moments routed to production tools. A safety team may need structured findings sent to reporting. A training team may need lesson segments indexed for learning products. A product team may need vector search for video scenes and events powering user-facing discovery or recommendations.
VideoVector supports exports and webhook handoff so downstream systems can react when processing completes. Webhooks can notify internal services, trigger review queues, update catalogs, start analytics workflows, or move metadata into another system of record. The extracted output can include segment-level JSON, asset-level fields, metadata text, tags, timestamps, and search-ready descriptors.
The same automation pipeline can support search and VideoRAG. After extraction, media can be indexed for natural-language search, image and multimodal vector retrieval, structured filters, SQL search, multi-run comparison, and agentic retrieval. That means automated ingestion is not only a storage convenience. It feeds the retrieval layer that applications use for archive discovery, scene search, content recommendations, compliance review, and grounded media assistants.
For developers, the VideoVector API provides programmatic control over the workflow. Applications can create indexes, submit media, run prompts, retrieve results, search outputs, and coordinate exports. The API makes it possible to place VideoVector inside existing cloud architecture instead of forcing teams into a separate manual process.
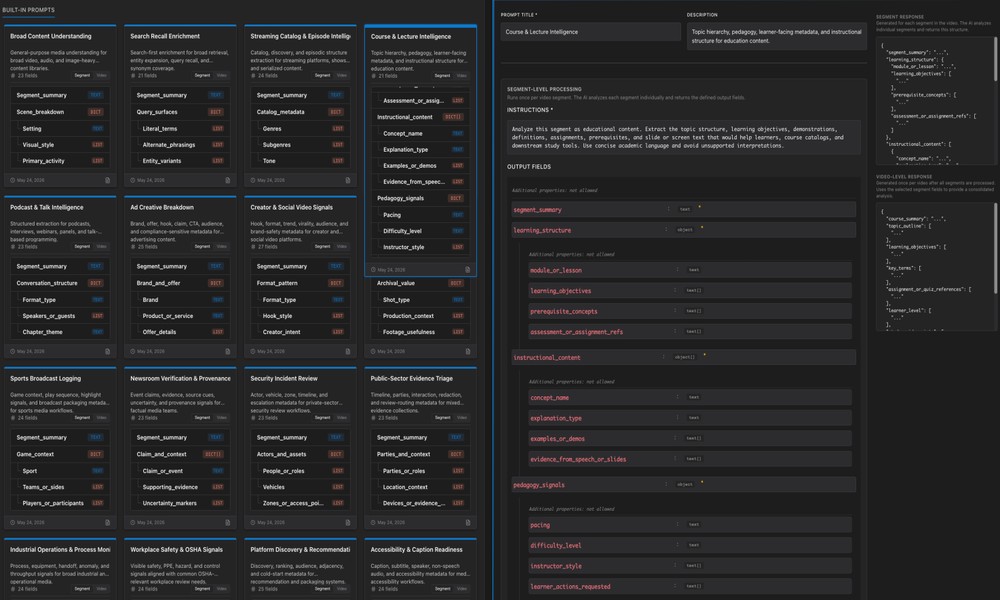
The value of automation compounds after a schema is proven. A team can validate a schema for video scene extraction or video segment analysis, then run it repeatedly across incoming files. The output stays consistent enough for downstream services to trust. Search indexes update with new metadata. Webhooks alert systems when results are ready. Exports move structured intelligence into business workflows.
VectorMethods is built for teams that need media intelligence to leave the demo and enter production. VideoVector can process raw video, audio, and images, extract schema-backed metadata, power multimodal search, and automate delivery into existing systems. Teams planning governed archive, integration, or deployment work can use the VectorMethods contact path to map the first production workflow.
The end state is simple: raw media lands in cloud storage, VideoVector analyzes it, and structured intelligence flows to the systems that need it.